state and trace
We want the text to be simple, unsurprising. We want our readers to feel a sense of cozy familiarity.
When we say fiction belongs to a genre, we mean that it builds upon familiar themes and structures. By assigning a genre — a slasher flick, or a comedy of manners, or a murder mystery — we shape the audience's expectations. Genre is a locus; it makes the rest of the explanation less surprising.
And this is the point. People like genre fiction because it's familiar; it can be read easily, or even mindlessly. Literary fiction, on the other hand, challenges the reader. Its goal, according to theorists, is to make the familiar feel strange:
[T]he essential function of poetic art is to counteract the process of habituation encouraged by routine everyday modes of perception. We very readily cease to 'see' the world we live in, and become anaesthetized to its distinctive features. The aim of poetry is to reverse that process, to defamiliarize that with which we are overly familiar, to 'creatively deform' the usual, the normal, and so to inculcate a new childlike, non-jaded vision in us.1
When we create software, however, our sympathies must lie with the genre writer. We want the text to be simple, unsurprising. We want our readers to feel a sense of cozy familiarity.
We should, then, try to understand how genres create this familiarity. We can begin with the story beats; the events that comprise the narrative. We will call this the story's trace. Each of the events in this trace represent a change to the state of the story. This state is a structure, comprised of the key entities and their relationships.
These key entities are what shape the narrative. They make the trace predictable; each part of the state helps us anticipate future states. In fiction, this structure is usually learned through repetition; we must read, and compare, many stories within the same genre.
Let's consider the structure of a murder mystery, as popularized by Agatha Christie. These stories follow a familiar sequence: a murder occurs, a detective is called in, each suspect is interviewed, and then the murderer is revealed. Each event, as it occurs, updates our state:
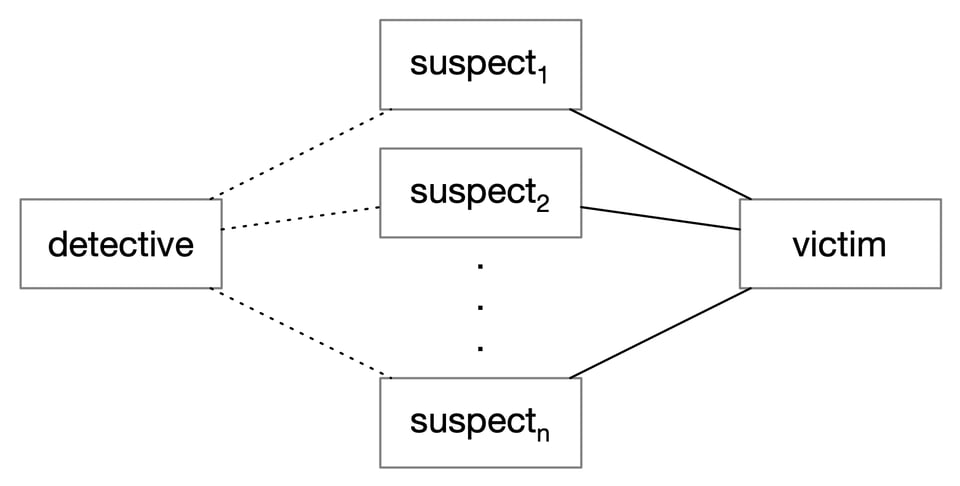
This structure is quite sparse. There is no place for incidental characters or incidental relationships; everything relates to the murder. In an archetypal murder mystery, there are no aimless conversations, no quiet interludes. Each event is understood as bringing us closer to learning whodunnit.
The obvious locus is the victim, who has a strong relationship to all of the suspects. The relationship between the suspects and detective is much weaker; most detectives are itinerant, solving murders under a variety of circumstances and in a variety of locales.2
Structural analysis of fiction tends to focus on the story's trace.3 On the face of it, this seems quite reasonable; the state, after all, is simply the sum of past events. We can adopt a similar perspective when looking at the implementation of a database. As Pat Helland puts it:
Transaction logs record all the changes made to the database. High-speed appends are the only way to change the log. From this perspective, the contents of the database hold a caching of the latest record values in the logs. The truth is the log.4
Datastores such as Apache Kafka take this to its logical conclusion: they only provide a log of events, a trace. State is derived by the application.
But consider this scenario: you're watching a television show, and are deep into its fourth season. A friend sits down beside you. They've never seen the show before. "But that's fine," they say, "just catch me up."
You will not, in this situation, recite every event of the past four seasons. Most of those events, at this point, don't matter. They belong to story lines that have long since been resolved. Our trace, it turns out, contains narrative arcs:
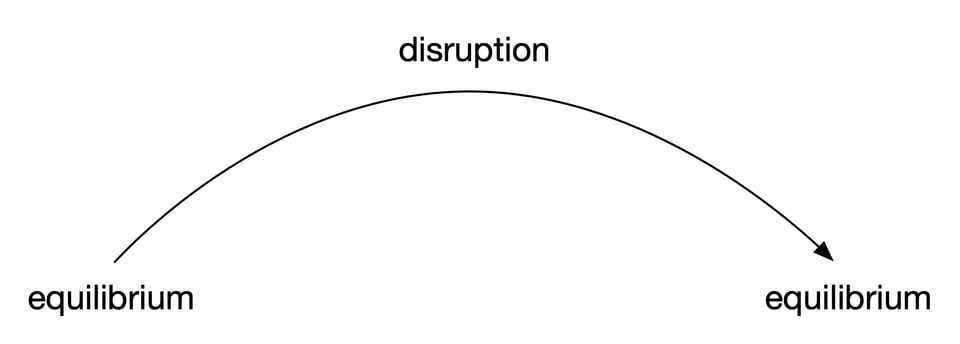
A narrative arc offers closure; once complete, it congeals into the sum of its events. It allows us to focus on the present state, the new equilibrium. Our explanation to our friend will be similarly biased towards the present. We will focus on the state of the narrative; if we discuss events, that suggests a narrative arc which is still in-flight.
Similarly, databases continually compact their transaction logs. The transactions are, themselves, narrative arcs; we don't store every step of a transaction, only its outcome. And in applications built atop Kafka, it's impractical to store and process an ever-growing log of events. There will, inevitably, be mechanisms for the derived state to be cached, and the trace to be truncated.
Our software is full of narrative arcs. Consider, for instance, that pure functions — functions without any side-effects or context-dependence — are referentially transparent. This means that function invocation and the return value are interchangeable:
val x = 2 + 2
val x = 4
We can, in other words, ignore what happens inside a pure function. All that matters is how it ends. We can even, if we're careful, apply this logic to less-pure functions:
val config = load_config_file()
Here, our config value depends on the contents of the config file. Different executions may produce different traces. But within a given trace, once we have config, it doesn't really matter what happened inside load_config_file(). All that matters is how it ended.
It's instructive to consider how we use debuggers. We can, if we like, step through our programs one instruction at a time. We can peel away the narrative arcs, examine the raw trace. In practice, however, we never start at the beginning; we start at our breakpoint. And only then, after billions of instructions have elapsed, do we sit down and ask to be caught up.
We cannot, then, understand our software solely through its trace. There are too many events, and too few with any real importance. We must layer narrative arcs atop the endless details of our software's execution, and then look to its state.
Unlike in fiction, our software's state is explicitly modeled. It is, essentially, the graph of in-memory data. Even as this graph changes, its topology remains redundant, unsurprising. The text of our software is organized around the structures within its state.
Consider if this weren't the case. Dijkstra, in Go To Statement Considered Harmful, argues for the opposite:
[W]e should do ... our utmost ... to make the correspondence between the program (spread out in text space) and the process (spread out in time) as trivial as possible.5
When implementing a function, this is good advice. When we read a function, we are usually trying to understand its trace. The text of our function should make that as easy as possible.
This argument, however, breaks down at larger scales. If two functions are called in sequence, they don't need to sit side-by-side in our codebase. And that sequence, in any case, may vary with our inputs. There's little point in trying to mirror the trace of our software in its text.
This is why, in nearly every language and every project, the text of our software is organized around datatypes. Together, these datatypes comprise our software's model; each is defined by their relation to that whole. And, in turn, facets of that model are reflected in our software's state.
Software, however, is as much a machine as it is a text. We must be able to reason about its execution, even as the trace grows impossibly large. Narrative arcs are central to the practice of software design.
And so, we must explore both: the structures within our software's state, the narrative arcs atop our software's trace, and the ways in which each shapes the other.
-
Hawkes 2003, p. 47 ↩
-
Even Miss Marple, who spends most of her time in the South of England, sometimes vacations in the Caribbean. ↩
-
See, for instance, Joseph Campbell's The Hero With a Thousand Faces, Vladimir Propp's Morphology of the Folktale, and Tzvetan Todorov's Grammar of the Decameron. ↩
-
Hey Zach, I like this latest iteration. The references to poetry and 2 types of fiction are fun to consider.
Found a tiny typo: "one instruction at at time"
Hope all is well! -Aaron
Add a comment: